

 P2T YoloV7 数学公式检测模型开放购买
P2T YoloV7 数学公式检测模型开放购买type
Post
status
Published
date
Jun 19, 2023
slug
p2t-yolov7-for-zsxq-20230619
summary
Pix2Text (P2T) 中的数学公式检测模型 YoloV7 开放购买了。
tags
星球专享
模型下载
Pix2Text
P2T
数学公式检测
MFD
category
开源工具
icon
password
URL
Rating
如 Pix2Text (P2T) 新版公式检测模型 末尾所说,不同版本的模型,一般会遵循以下的使用逻辑(很抱歉,开源作者也要喝咖啡,开源作者也可以有不开源的东西):
- 最新的模型供 P2T网页版 使用,以及付费购买;
- 次新的模型对星球会员开放,及支持单独购买;
- 次次新的模型对所有人免费开放。
YoloV7 模型当前包含两个版本:
version-20230208:第一版的YoloV7模型,大致训练于2023/02/08。P2T网页版 在2023/02~2023/06 期间,用的是此检测模型。
version-20230613:第二版(最新版)YoloV7模型,训练于2023/06/13,P2T网页版当前正在使用此模型。此模型主要针对中文图片中的数学公式,以及纯公式窄图片场景做了优化。具体说明见:Pix2Text (P2T) 新版公式检测模型。
获取方式
当前这两个版本的获取方式如下:
检测模型版本 | 企业购买 | 个人购买 | 对星球会员 | 免费可下载 |
YoloV7_Tiny 开源模型 | ✖️ | ✖️ | ✔️ | ✔️ |
version-20230208 | ✖️ | ✔️ B站工房 | ✔️ 免费 | ✖️ |
version-20230613 | ✔️ 八折 | ✖️ |
效果对比
相对于开源可免费使用的 YoloV7_Tiny 模型,YoloV7 模型大概是其
6倍大,训练消耗的资源也差不多是这个倍数。下图是两个模型在测试集上效果的对比图(每个metric的具体含义请Google或者ChatGPT,它们都是越大越好)。注意,下图蓝线是
version-20230613 版本的训练过程,之前的 YoloV7 模型(version-20230208)的训练图找不到了。。但相对高低可以参考,version-20230613 主要是优化了中文图片和窄的孤立公式图片的检测效果。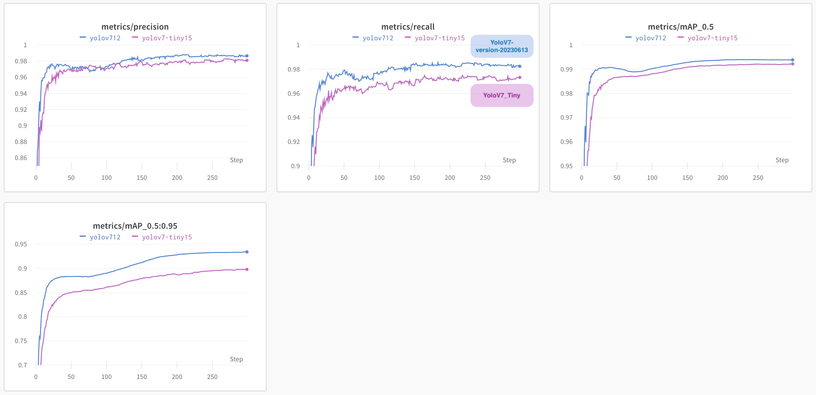
从上图可以看到 YoloV7 相比 YoloV7_Tiny 模型,精度还是要好不少的,比如其召回率从 0.973 提升到了 0.985(能检测出更多公式)。
YoloV7 模型使用说明
比如默认使用开源的MFD检测模型 YoloV7_Tiny,使用方法如下:
首先从前面表格中的方式下载模型文件(40~50+M),解压后会看到一个名为
yolov7-model 的文件夹,里面的文件即为模型文件,比如叫 mfd-yolov7-20230208.pt 。假如文件 mfd-yolov7-20230208.pt 的路径为 abc/def/yolov7-model/mfd-yolov7-20230208.pt,那在初始化 Pix2Text 时应该如下传入参数。初始化后的使用方式和开源模型完全一样,检测和识别结果也没有差别。有问题可以在这里评论,或者加入群聊与我沟通,谢谢。
- 作者:Breezedeus
- 链接:https://www.breezedeus.com/article/p2t-yolov7-for-zsxq-20230619
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章












