

 Pix2Text (P2T) 新版公式检测模型
Pix2Text (P2T) 新版公式检测模型type
Post
status
Published
date
Jun 13, 2023
slug
p2t-mfd-20230613
summary
今天更新了 Pix2Text (P2T) 中的公式检测模型,优化了中文图片中的公式检测效果,以及对单独公式图片的检测效果。
tags
P2T
数学公式检测
数学公式识别
MFD
Pix2Text
工具
category
开源工具
icon
password
URL
Rating
Pix2Text (P2T) 介绍
Pix2Text (P2T) 期望成为 Mathpix 的免费开源 Python 替代工具,目前已经可以完成 Mathpix 的核心功能。P2T 自 V0.2 开始,支持识别既包含文字又包含公式的混合图片,返回效果类似于 Mathpix。P2T 的核心原理见下图(文字识别支持中文和英文):

P2T 使用开源工具 CnSTD 检测出图片中数学公式所在位置,再交由 LaTeX-OCR 识别出各对应位置数学公式的Latex表示。图片的剩余部分再交由 CnOCR 进行文字检测和文字识别。最后 P2T 合并所有识别结果,获得最终的图片识别结果。感谢这些开源工具。
数学公式检测模型更新 (2023/06/13)
数学公式检测(Mathematical Formula Detection,简称 MFD)其实是放在 CnSTD 项目中的,P2T 只是调用 CnSTD 的这个模型罢了。所以本次更新也是 CnSTD 模型的更新。
加入混合图片
P2T网页版 自发布以来,其实已经积累了很多用户的真实调用图片。前两周我花了不少时间,对其中的部分做了标注。标注对象主要针对中文图片。之前的MFD模型其实对英文的检测效果已经相当不错了,但是中文比较差。当时训练的中文数据只有我自己合成的 CnMFD Dataset,缺乏真实图片。所以之前的模型对中文真实图片效果一般,尤其是中学试题类的图片。
这次新标注的数据,主要是既包含文字又包含数学公式的混合图片,其中又会重点关注中文的文字图片。以下是一些代表性图片:
代表性混合图片




为了标注这些图片,我又倒腾了下标注工具 Label Studio,下次专门写篇文章,介绍下如何用 Label Studio 导入本地图片,以及预测结果等。
加入纯公式图片
在标注过程中,发现之前的模型对于很窄(宽度小)的只包含一两个数学符号的纯公式图片识别的不好。
代表性纯公式图片

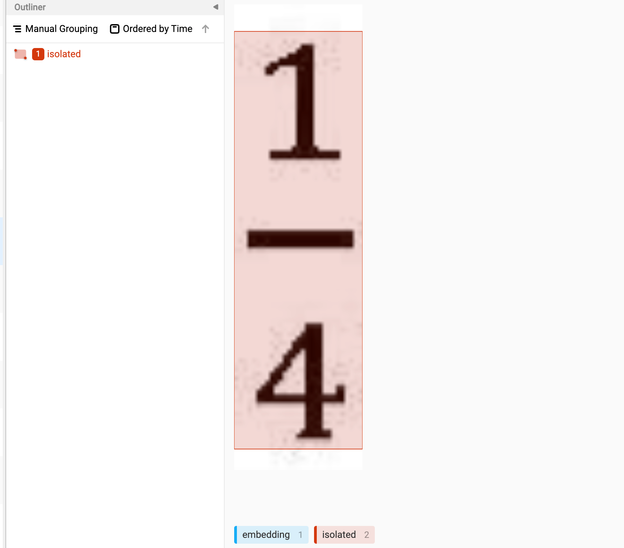
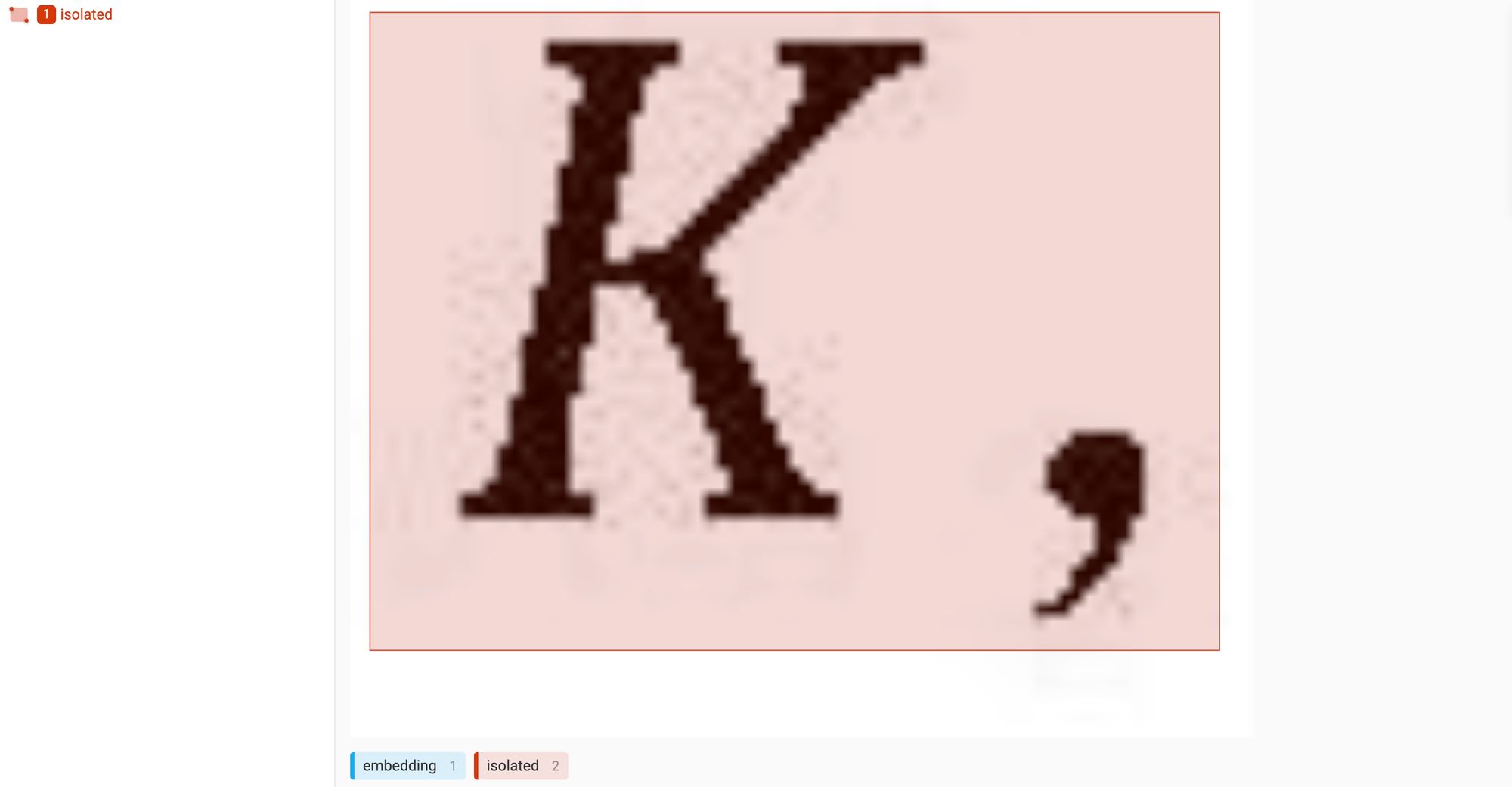

主要原因也是之前的训练数据中几乎没有纯公式的图片数据。
这个数据倒是基本不用标,之前在合成 CnMFD Dataset 数据时我就抽取了很多纯公式的图片patches,只要从这里面找出来一些代表图片即可。
这两种新的数据,相对于原有的训练数据,大概各加了
10% 左右到训练数据中。训练后得到的新模型,对中文图片中的数学公式,以及纯公式窄图片的检测效果,要明显优于之前的模型。
这个新模型今天(06-13)已经部署到 P2T网页版,暂不对外开放下载,专供网页版使用,欢迎大家去体验下。
后续会把网页版之前使用的 MFD YoloV7 模型开放给 知识星球 CnOCR/CnSTD私享群 的朋友。YoloV7 模型到目前为止只在之前的网页版可体验,还没对其他人开放过。
不同版本的模型,一般会遵循以下的使用逻辑:
- 最新的模型供 P2T网页版 使用,以及付费购买;
- 次新的模型对星球会员开放,及支持单独购买;
- 次次新的模型对所有人免费开放。
【Update 2023-06-22】
- 模型已开放购买,具体见:P2T YoloV7 数学公式检测模型开放购买 。
- 作者:Breezedeus
- 链接:https://www.breezedeus.com/article/p2t-mfd-20230613
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章











