

type
Post
status
Published
date
Apr 19, 2024
slug
llama3
summary
LLaMA 3 又来掀桌子了,发布一天后排名已经到开源模型首位了,已超过早期的 GPT4 和 Gemini Pro 🔥🔥🔥。哪些因素带来了新的精度提升?
tags
LLM
GPT4
Generative
NLP
大语言模型
ChatGPT
Meta
LLaMA3
category
技术分享
icon
password
URL
Rating

Meta 开源的 Llama LLM 系列模型已经成为了 LLM 界的 Android 系统。Meta 发布新模型的同时也会发布模型的训练细节,所以非常值得一追。
Llama 3 应该会分三次才能发布完所有模型,所以我称之为掀桌子三部曲:
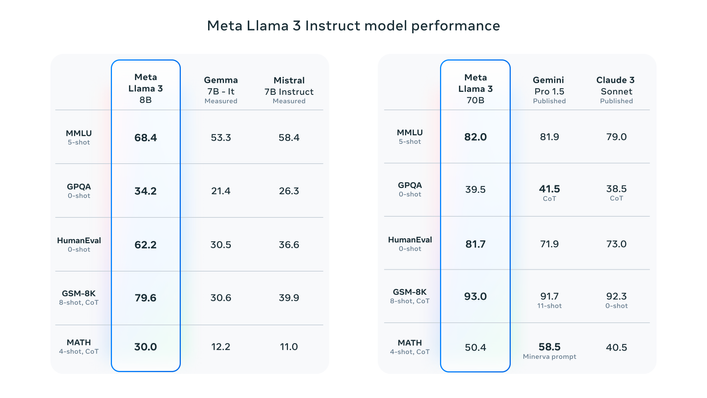
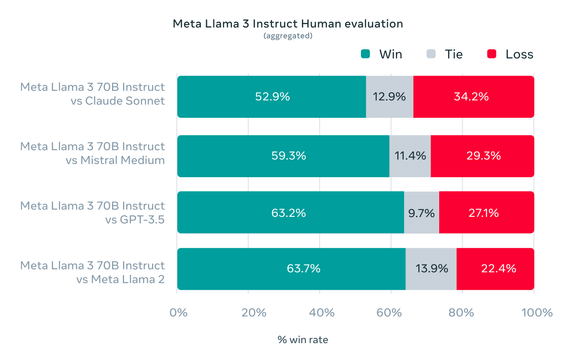
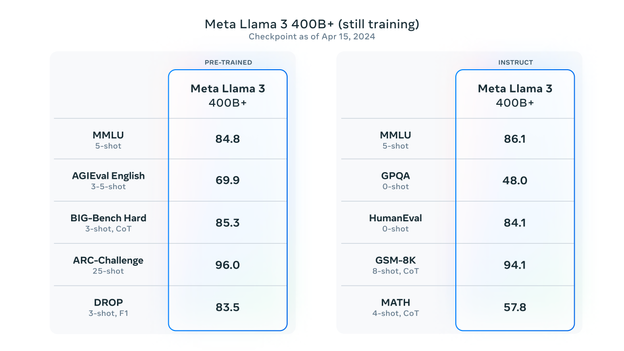
LLaMA 3 来了,今天发布了两个 size 的模型:8B 和 70B。8B 的模型刷新了同尺寸模型的效果。70B 模型的效果界于 GPT3.5 ~ GPT4 。400B 模型(还在训练)可能在评测集上的效果优于 GPT4。
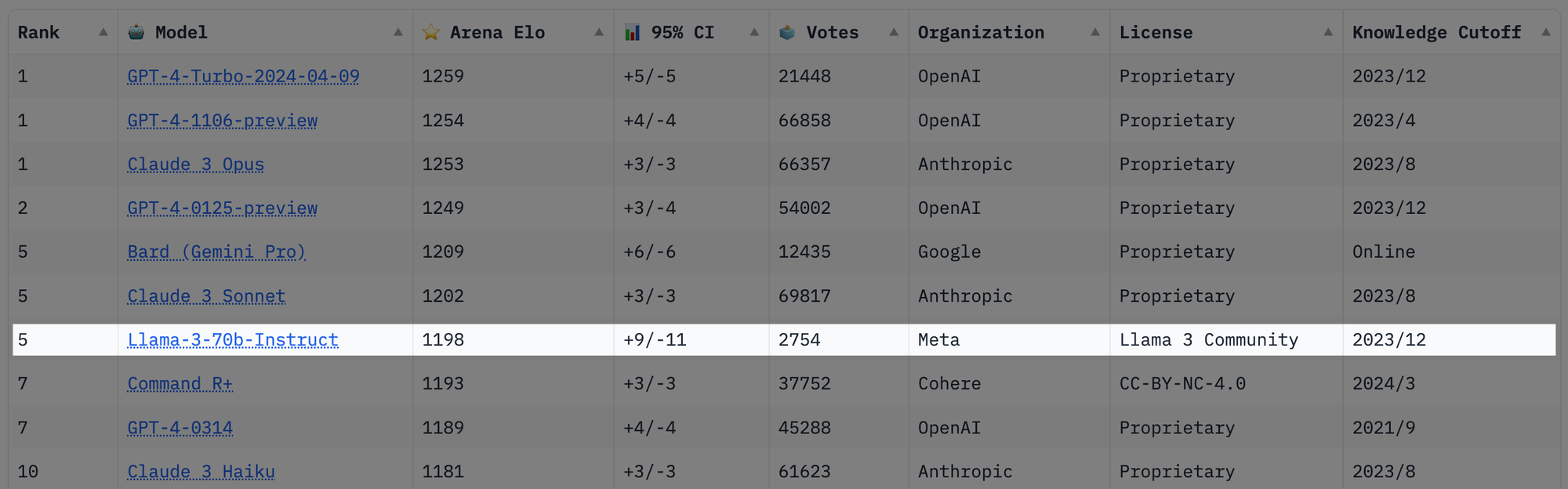
发布一天后排名已经到开源模型首位了,已超过早期的 GPT4 和 Gemini Pro 🔥🔥🔥。
<ins/>
免费在线使用
可以使用下面的地址试试效果,确实还是可以的。


模型架构
- LLaMA 3 依旧使用的是 decoder-only transformer 架构。
- LLaMA 3 使用了 128K token vocabulary (LLaMA 2 是 32K),提升了编码效率,从而大幅提高了模型性能。
- 采用了分组查询注意力(GQA),提升了推理效率。
- 在长度为 8,192 长度的 token 序列上训练(之前是 4K),并使用掩码确保自注意力不会跨越文档边界。
预训练数据
- LLaMA 的预训练数据都来自公开数据,高达 15T tokens(LLaMA 2 是 2T),其中的代码数据增加了 4 倍。
- 为应对未来的多语种应用场景,LLaMA 3 预训练数据集中有超过5%是30多种语言的高质量非英语数据。
- 为确保 LLaMA 3 训练用的是最高质量的数据,作者开发了一系列数据过滤流水线,包括使用启发式过滤器、NSFW过滤器、语义去重方法和文本质量分类器等。作者发现,前几代LLaMA在识别高质量数据时表现出乎意料的出色,因此使用LLaMA 2生成了用于训练LLaMA 3文本质量分类器的训练数据。
- 作者进行了大量实验,评估在最终预训练数据集中混合来自不同来源的数据的最佳方式。这些实验使作者能够选择一种数据混合方式,以确保LLaMA 3在包括谜题问答、STEM、编程、历史知识等各种cases中表现良好。
- 作者利用 scaling law 来优化数据组合比例和计算资源。虽然 8B 模型对应的 Chinchilla-optimal 数据量大致为 200B tokens,作者发现就算是用 15T 的数据训练也能保持 log-linearly 的趋势不断更好。
参考 张俊林:https://weibo.com/u/page/fav/1660835355
一般模型大小乘以20,就是Chinchilla law对应的最优训练数据量,比如对于8B模型,160B训练数据对应最优Scaling law。但是,我们不能机械地理解和应用Scaling law,从Chinchilla的论文实验数据可以看出,还有另外两条路提升模型性能,尽管它不是训练最优的。一个是固定住模型大小,持续增加训练数据,模型效果会持续变好,只要你有源源不断的新数据能加进来,那么小模型就能效果持续变好;另外一个是固定住训练数据量,那么你持续放大模型参数规模,同样的,模型效果也会越来愈好。如果我们把按指定比例同时增加训练数据和模型容量叫做“Optimal Chinchilla Law”,那么这两种做法可以被称为“Sub-optimal Chinchilla Law”。
- 在两个自建的24K GPU集群上进行了训练。为最大化GPU运行时间,开发了一个先进的新训练堆栈,可自动执行错误检测、处理和维护。作者还大大改善了硬件可靠性和无声数据损坏检测机制,并开发了新的可扩展存储系统,减少了检查点和回滚的开销。这些改进使LLaMA 3的有效训练时间超过95%。相比LLaMA 2,这些改进将 LLaMA 3 训练效率提高到约三倍。
指令微调
- 后训练方法结合了监督式微调(SFT)、拒绝抽样、proximal policy optimization(PPO) 和 direct policy optimization(DPO)。用于SFT的prompts,以及用于PPO和DPO的偏好排序数据质量对于得到对齐的模型性能影响重大。模型质量的一些最大提升来自于精心处理这些数据,并对人工标注进行多轮质量保证。
- 通过PPO和DPO从偏好排序中学习大大提高了 LLaMA 3 在推理和编码任务上的性能。作者发现,如果问一个模型它难以回答的推理问题,该模型有时会产生正确的推理过程:模型知道如何得到正确答案,但不知如何选择它。在偏好排序上训练使模型学会了如何做出选择。
第三方评测
清华团队给出的评测效果:


LLaMA系列的更多介绍资料


一大波在路上的 Chinese LLaMA 3
直接 GitHub 上搜就行:
<ins/>
References
- 作者:Breezedeus
- 链接:https://www.breezedeus.com/en/article/llama3
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章









