

 Pix2Text V1.0 新版发布,带来了最好的开源数学公式识别模型
Pix2Text V1.0 新版发布,带来了最好的开源数学公式识别模型type
Post
status
Published
date
Feb 26, 2024
slug
p2t-v1.0
summary
Pix2Text (P2T) V1.0 发布,其中新的公式识别模型(MFR)精度得到极大提高,是当前精度最高的开源公式识别模型。
tags
数学公式识别
Math-Formula-Recognition
MFR
Pix2Text
P2T
LaTeX-OCR
Math-OCR
数学公式检测
工具
版面恢复
LaTeX
Nougat
Texify
category
开源工具
icon
password
URL
Rating

Pix2Text (P2T) 识别图片中文字和数学公式,输出对应的文本和 Latex 表达式;其目标是成为 Mathpix 的免费开源 Python 替代工具。Pix2Text 是 2023 年 2 月份发布的初版,距离现在差不多刚一年,GitHub stars 也刚突破 1000,这是个典型的缓慢积累的项目。
过去的一年中,大模型(LLM 或 LMM)发展迅速,很自然也有人尝试利用大模型来解决版面分析或数学公式识别问题。其中最受关注的当属 Meta 开源的模型 Nougat。之后又出了号称精度更高的 Texify。这两个项目对应的模型文件大小在 1G 左右。后来旷视又出了更大的 7B 模型 Vary,以及后续的 2B 模型 Vary-toy。这些模型对标准排版的图片,尤其对英文文字背景下的标准排版图片,其识别精度还是很高的。但是对于非标准排版的图片,比如中学试题,PPT,或者来自 Word 的各种奇葩排版,识别精度还是挺差的。这些大模型的另一个缺点是识别速度慢,它们基本都要求在 GPU 上才能批量运行。
如我之前所说,Pix2Text 是坚持走 小模型+开源 的路线,模型大小得保证在一般的 CPU 机器上能跑得动,代码和基础模型都开源,同时也提供精度更高的付费模型供购买后个人或商业使用。Pix2Text 首先利用数学公式检测(MFD)模型检测出图片中公式所在的位置,然后由数学公式识别(MFR)模型识别出公式部分的 LaTeX 表示,再利用文字识别引擎识别图片其他部分的文字内容。所有识别结果融合后获得最终的图片识别结果。具体原理说明见 Pix2Text (P2T) 。
过去的半年中 Pix2Text 的进步还是蛮大的。我在 2023 年 6 月份先是训练了新的公式检测(MFD)模型,然后接着在 2023 年 7 月份训练了新的公式识别(MFR)模型,免费使用的 P2T网页版 也一直在缓慢进步中。在 2024 年 1 月份发布的 V0.3 中,Pix2Text 的文字识别引擎支持
80+ 种语言,如英文、简体中文、繁体中文、越南语、法语等。这次新发布的 Pix2Text V1.0,最大变化是 MFR 使用了新的模型架构,精度得到极大提升。之前的模型架构来自于 Latex-OCR ,可惜这个项目基本不更新了,其代码质量也很一般,各种依赖包也很陈旧,维护成本太高。所以 Pix2Text V1.0 移除了对 Latex-OCR 这个项目的依赖,新的 MFR 模型架构使用了微软的 TrOCR 。Pix2Text V1.0 开源的 MFR 模型,其识别数学公式图片的精度已经远超我所知的各种开源模型,如 Latex-OCR,Texify,和 Pix2Text 之前版本的所有 MFR 模型(包括付费模型),已经可以与 Mathpix 以外的其他商用模型掰掰手腕了。具体说明如下。
<ins/>
不同 MFR 模型精度对比
测试数据对应的原始图片来源于 Pix2Text 网页版 用户上传的真实数据。首先选取一段时间内用户的真实数据,然后利用 Pix2Text 中数学公式检测模型(MFD)检测出这些图片中的数学公式并截取出对应的部分,再从中随机选取部分公式图片进行人工标注。就获得了用于测试的测试数据集了。下图是测试数据集中的部分样例图片。从中可以看出测试数据集中的图片比较多样,包括了各种不同长度和复杂度的数学公式,有单个字母的图片,也有公式组甚至矩阵图片。本测试数据集包括了
485 张图片。
以下是各个模型在此测试数据集上的 CER(字错误率,越小越好)。其中对真实标注结果,以及每个模型的输出都首先进行了标准化,以保证不会因为空格等无关因素影响测试结果。对 Texify 的识别结果会首先去掉公式的首尾符号
$或$$。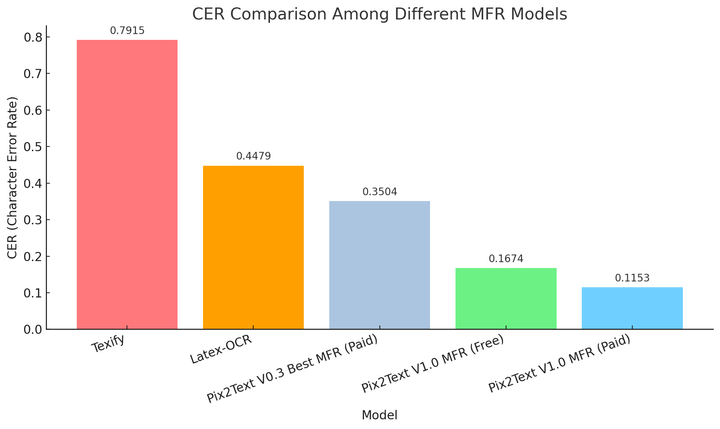
由上图可见,Pix2Text V1.0 MFR 开源免费版模型已经大大优于之前版本的付费模型。而相比 V1.0 MFR 开源免费模型,Pix2Text V1.0 MFR 付费模型精度得到了进一步的提升。
如前所述,Texify 更适用于识别标准排版的图片,它对包含单字母的图片识别较差。这也是 Texify 在此测试数据集上效果比 Latex-OCR 还差的主要原因。
效果示例
接下来展示一些示例,可以看看新版 Pix2Text V1.0 MFR (Paid) 对公式的识别效果。
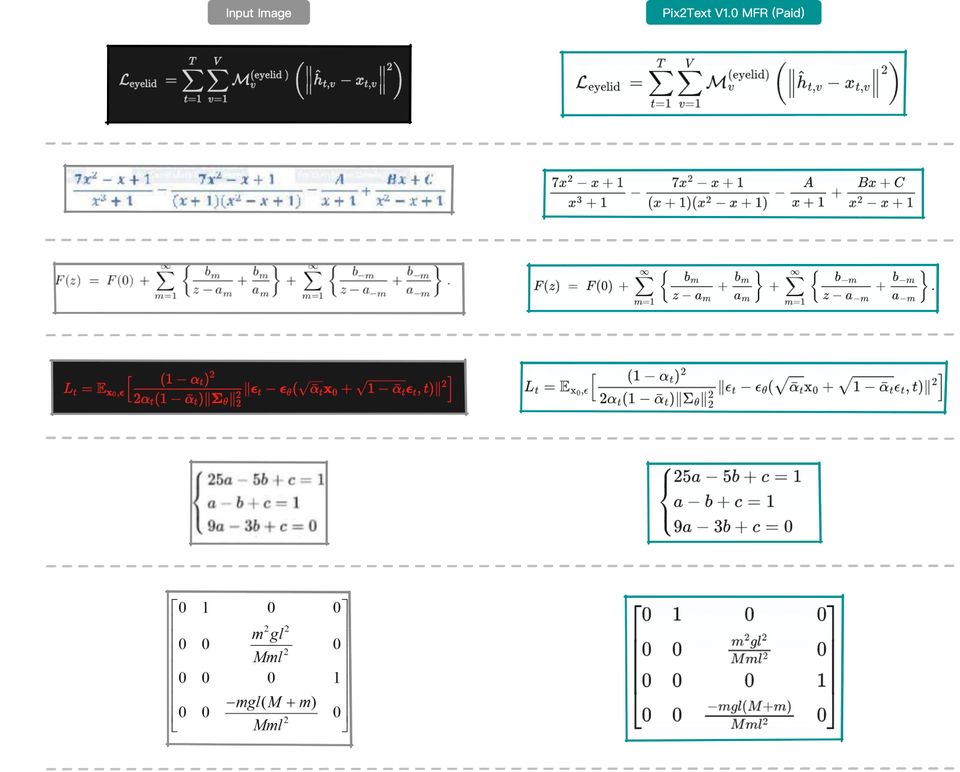
下图展示了模型在一些印刷体公式图片上的效果。其中左侧为原图(原图见 Pix2Text Github 仓库),右侧为MFR 识别后渲染后的效果图。
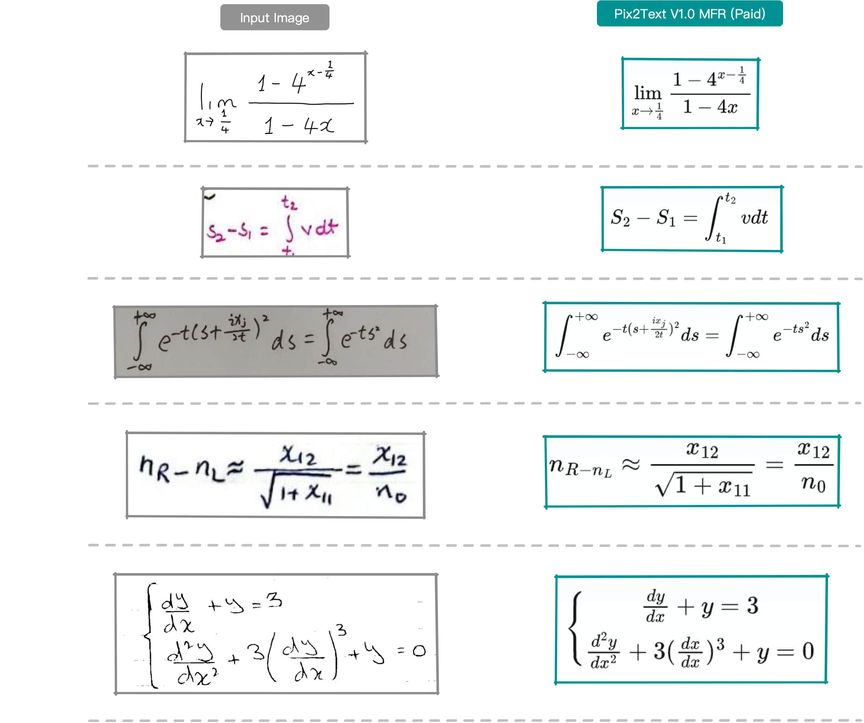
下图展示了模型在一些手写体公式图片上的效果。其中左侧为原图(原图见 Pix2Text Github 仓库),右侧为MFR 识别后渲染后的效果图。
P2T 网页版

所有人都可以免费使用 P2T网页版,每人每天可以免费识别 10000 个字符,正常使用应该够用了。请不要批量调用接口,机器资源有限,批量调用会导致其他人无法使用服务。
受限于机器资源,网页版当前只支持简体中文和英文,要尝试其他语言上的效果,请使用以下的在线 Demo。
<ins/>
在线 Demo


可以使用此 在线 Demo 尝试 P2T 在不同语言上的效果。但在线 Demo 使用的硬件配置较低,速度会较慢。如果是简体中文或者英文图片,建议使用 P2T网页版。
如果无法科学上网,可以访问此地址:https://hf-mirror.com/spaces/breezedeus/Pix2Text-Demo 。
付费版模型购买
购买链接
V1.0 MFR 【个人版】购买链接:bilibili 工房。此链接购买后的模型仅限个人使用,不可商用,不可开发票。此商品仅包含模型的 ONNX 版本,不包含 PyTorch 版本。企业商用或开发票请见以下说明。MFD【个人版】购买链接:bilibili 工房 。
Pix2Text V1.0+ 包含两种企业版。它们的权益差异见下图。企业 Pro 版 是一次性购买,之后有新模型需要重新购买。企业 Pro 版 只允许企业内部使用或者对外提供免费的服务(如教育机构),不允许对外提供付费服务。企业 Plus 版 购买后一年内可以免费获取所有的新模型。企业 Plus 版 除了提供 Pro 模型外也提供 Plus 版 模型,同时提供所有模型的 PyTorch 版本,企业可以基于这些模型利用自己的数据进行模型精调,或者转换为需要的其他模型格式(如 CoreML等)。企业 Plus版 允许企业对外提供付费服务。
更详细说明请见 模型购买商店(进入商品的详情页有具体说明)。

购买链接见:模型购买商店(进入商品的详情页有具体说明)。
使用说明
通过模型购买商店购买企业 Basic 版后,可以下载模型对应的 2 个压缩文件,其中以
p2t-mfd- 开头的文件为 MFD(数学公式检测)模型,以p2t-mfr- 开头的文件为 MFR(数学公式识别)模型。MFD 模型压缩文件解压后会看到一个名为 yolov7-model 的文件夹,里面的文件即为模型文件,比如叫 mfd-yolov7-20230613.pt 。假定文件 p2t-mfr-20230702.pth 的路径为 abc/def/yolov7-model/p2t-mfr-20230702.pth。MFR 模型压缩文件解压后会看到一个名为 mfr-pro-onnx 的文件夹,其中包含模型文件以及相关的配置文件。假定文件夹 mfr-pro-onnx 的路径为 abc/def/mfr-pro-onnx。那在初始化 Pix2Text 时应该如下传入参数。初始化后的使用方式和开源模型完全一样,检测和识别结果的结构也是一样的。
如果购买的是企业 Pro 订阅版,可以下载的模型文件会更多(当前是 5 个),除了包含 MFR 的 PyTorch 版本外,也会包含 CnOCR(文本 OCR)中的最新付费模型(ONNX 和 PyTorch 版本),它对中英文文本的识别效果比免费模型更好。可以使用如下方式传入对应的模型。
注意:CnOCR 的文本模型只支持英文和简体中文,如果要识别其他语言的文本,请勿使用 CnOCR 模型。只需把上面代码中的
text_config 去掉即可。分享视频

- 作者:Breezedeus
- 链接:https://www.breezedeus.com/en/article/p2t-v1.0
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章











