

 CnOCR 纯数字识别新模型
CnOCR 纯数字识别新模型type
Post
status
Published
date
Oct 1, 2023
slug
cnocr-number-model-20231001
summary
CnOCR 中新加入了纯数字识别新模型,适合银行卡号识别、身份证号识别、硬币年份识别等应用场景。
tags
星球专享
模型下载
CnOCR
数字识别
OCR
Nougat
文字识别
category
开源工具
icon
password
URL
Rating
.jpeg?table=block&id=ff222eeb-453e-4dde-9a7d-a29535d0f784&t=ff222eeb-453e-4dde-9a7d-a29535d0f784&width=1024&cache=v2)
为什么需要纯数字识别模型
有一些 OCR 应用场景,图片中的待识别文字只包含
0~9 的纯数字序列。例如银行卡号、身份证号(注意,中国的身份证有可能末尾出现字母)、硬币年份等。通用的识别模型用在这些应用场景效果往往不够理想。下面介绍下这系列纯数字识别模型的训练过程,以及使用方法。
训练数据集的构建
合成数据集
我合成了
1.7M+ 不同字体,不同长度的数字序列样本。一些示例如下:
真实数据集
除了合成数据,我从百度开源的一些场景OCR真实图片数据中过滤出只包含纯数字的
13k+ 的数字序列样本。同时,数据集中也包含了我自己标注的硬币年份真实图片
2k+ 样本。一些示例如下:
模型训练过程
训练使用的是 CnOCR V2.2.4 ,V2.2.4 训练时的数据增强借鉴了 Meta Nougat 中的增强方式,具体代码参见文件 cnocr/data_utils/transforms.py 。
整个系列模型主要包括3个模型:
densenet_lite_136-fc、densenet_lite_136-gru和densenet_lite_666-gru_large,它们都有对应的 PyTorch 和 ONNX 版本,所以总共有6个模型。densenet_lite_666-gru_large是比较大的模型,其他两个依旧继承CnOCR小模型的传统。三个模型的encoder结构都是densenet,只是前两个模型的densenet层数比较少,后面一个模型的densenet层数比较多。decoder结构有FC或者GRU(2层或者3层)。从模型名字基本可以看出它们的差异,具体模型配置可以参见 CnOCR 最新的代码 。模型的参数量和训练出的模型文件大小如下表。
ㅤ | densenet_lite_136-fc | densenet_lite_136-gru | densenet_lite_666-gru_large |
参数量 | 680 K | 1.4 M | 14.5 M |
文件大小 | 2.7 M | 5.5 M | 56 M |
PyTorch 版本 | ✔️ | ✔️ | ✔️ |
ONNX 版本 | ✔️ | ✔️ | ✔️ |
以下是训练过程各个指标对应的曲线图,可以看出
densenet_lite_136-fc、densenet_lite_136-gru和densenet_lite_666-gru_large 三个模型随着模型规模的变大,效果在稳定地变好。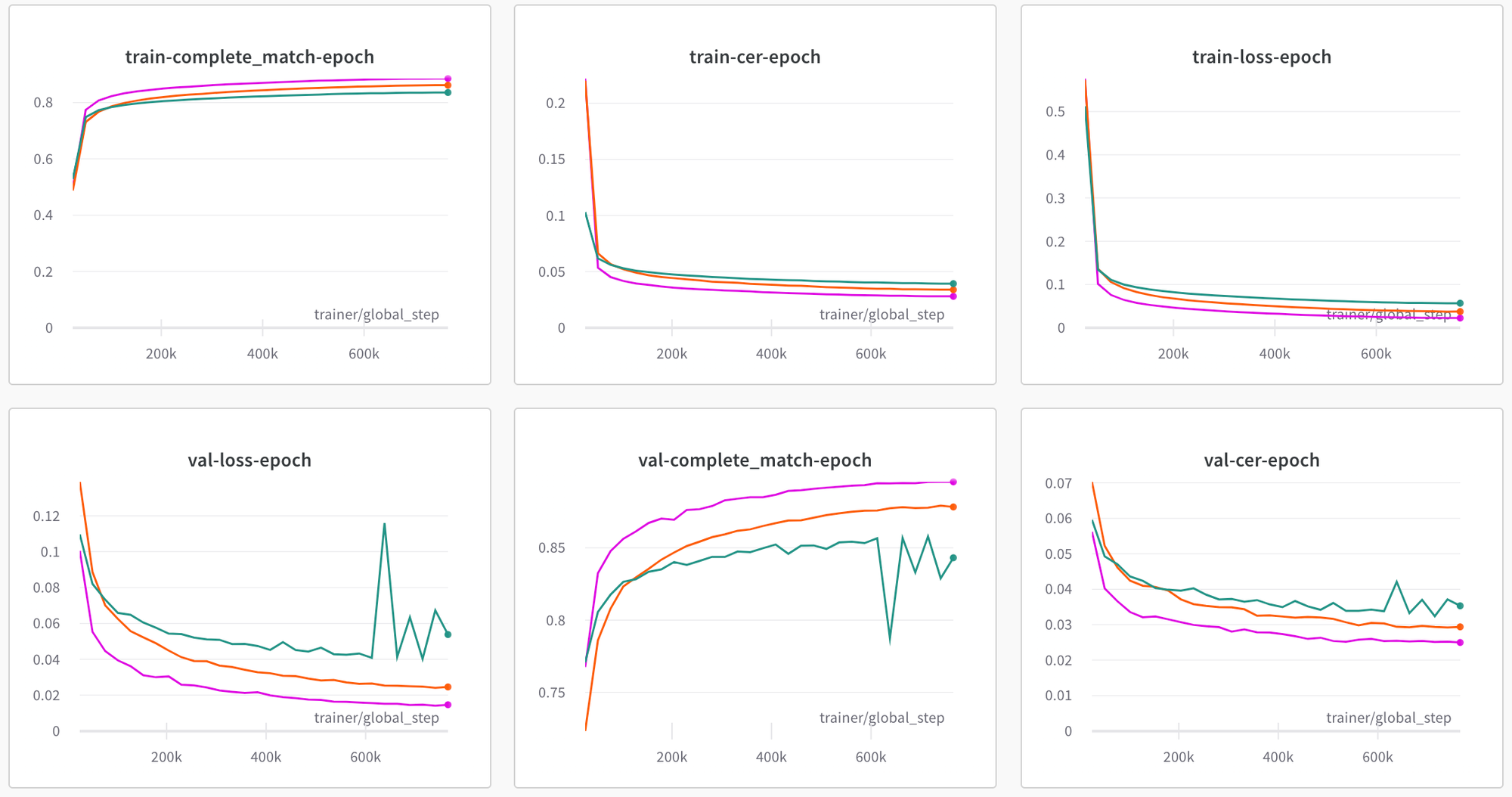
densenet_lite_136-fc:绿色;densenet_lite_136-gru:橙色;densenet_lite_666-gru_large:紫色。验证模型效果
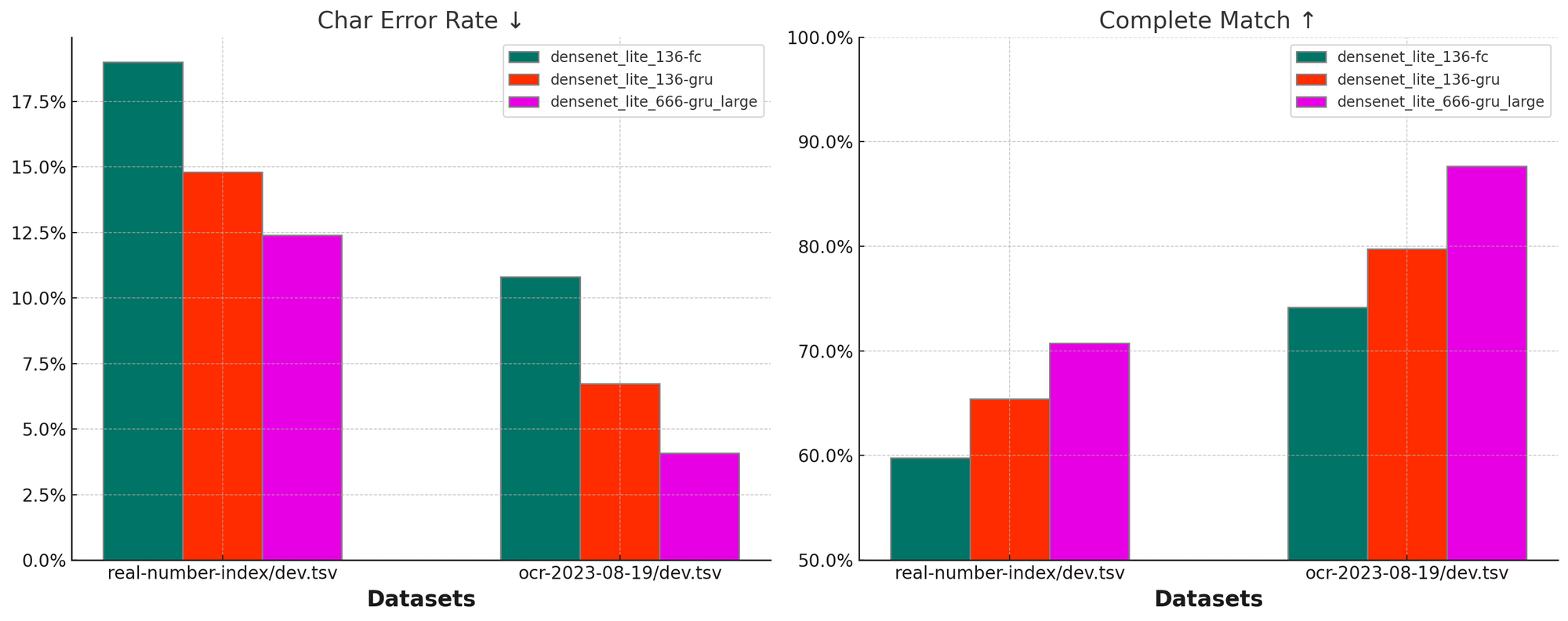
三个模型在两个真实数据集上的测试效果如下图。其中 Char Error Rate (CER) 为字错误率,值越低表示模型效果越好。而 Complete Match 表示所有测试样本中,模型预测完全正确(对一个样本的预测数字序列与其真实数字序列完全一致)的样本比例,故值越高表示模型效果越好。下图进一步验证了三个模型随着模型规模的变大,效果稳定变好的结论。
模型的获取方式和使用说明
3个纯数字识别模型在 CnOCR 中名字分别为:
number-densenet_lite_136-fc、number-densenet_lite_136-gru和number-densenet_lite_666-gru_large,增加了前缀 number-,以区分一般的识别模型。在线使用模型
可以在 CnOCR 在线 Demo 上传自己的照片验证这些纯数字识别模型的效果(多刷几次页面,或者使用梯子可访问,具体说明见 这里)。
这几个模型是识别模型,如需验证它们的识别效果,建议上传单行数字图片,然后在页面左侧勾选
单行文字模式(不使用检测模型)。否则检测模型会对最终效果有较大影响。下载模型离线使用
number-densenet_lite_136-fc 开源可直接免费下载,只需要安装 CnOCR >= V2.2.4.1 即可。number-densenet_lite_136-gru 目前仅星球会员可免费使用。number-densenet_lite_666-gru_large 需购买使用,购买链接见下表。模型的下载方式罗列如下:
检测模型版本 | 企业购买 | 个人购买 | 对星球会员 | 免费可下载 |
number-densenet_lite_136-fc | ✖️ | ✖️ | ✔️ | ✔️ |
number-densenet_lite_136-gru | ✖️ | ✖️ | ✔️ 免费 | ✖️ |
number-densenet_lite_666-gru_large | ✖️ | ✔️ 八折 | ✖️ |
下载模型zip文件后,把它们放于
~/.cnocr/2.2 目录(Windows下默认路径为 C:\Users\<username>\AppData\Roaming\cnocr)。CnOCR 会自动对其进行解压并使用(如有问题,请关注使用时输出的log信息)。一般应用场景
number-densenet_lite_136-fc 应该就够用。建议先用自己的应用图片(多试几张)在 CnOCR 在线 Demo 上验证效果后再决定是否要购买更大更高精度的模型。模型使用说明
首先,请确保你用开源的模型跑通了 CnOCR >= V2.2.4.1 ,否则你下载完付费模型也跑不起来。详细安装和使用说明看 CnOCR 在线文档 就行。遇到问题可以在这里评论,或者加入群聊与我沟通,但请注意帮你跑通代码不在星主的服务范围之内(参考 星球说明)。
使用方法和 CnOCR 中其他模型一样,只需要把识别模型名称对应的参数
rec_model_name 设置为对应的纯数字识别模型即可,使用方法如下:分享视频

有问题可以在这里评论,或者加入群聊与我沟通,谢谢。
- 作者:Breezedeus
- 链接:https://www.breezedeus.com/article/cnocr-number-model-20231001
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章












